2.注意力机制和Seq2seq模型 2.1.注意力机制 2.1.1.概念 2.1.2.框架 •不同的attetion layer的区别在于score函数的选择,在本节的其余部分,我们将讨论两个常用的注意层 Dot-product Attention 和 Multilayer ...
”q2 动手学 学习 模型 注意力机制 深度学习“ 的搜索结果
动手学深度学习:机器翻译及相关技术,注意力机制与seq2seq模型,Transformer 初次学习机器翻译相关,把课程的概念题都记录一下。 目录: 1、机器翻译及相关技术 2、注意力机制与seq2seq模型 3、Transformer 1、机器...
注意力机制与Seq2seq模型;Transformer机器翻译及其相关技术编码器和解码器编码器解码器束搜索贪婪搜索束搜索注意力机制与Seq2Seq模型计算背景变量Transformer 机器翻译及其相关技术 机器翻译(MT):将一段文本从一...
系统学习《动手学深度学习》点击这里: 《动手学深度学习》task1_1 线性回归 《动手学深度学习》task1_2 Softmax与分类模型 《动手学深度学习》task1_3 多层感知机 ...《动手学深度学习》task4_2 注意力机制和Seq2se
机器翻译及相关技术 Task2中的循环神经网络部分,有实现预测歌词的功能。在那个任务中,训练数据的输入输出...注意力机制 在“编码器—解码器(seq2seq)”⼀节⾥,解码器在各个时间步依赖相同的背景变量(context ve
【一】机器翻译及相关技术 机器翻译(MT): 将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出的是单词序列而不是单个单词。 输出序列的长度可能与...
最近参加了伯禹平台和Datawhale等举办的《动手学深度学习PyTorch版》课程,机器翻译及相关技术,注意力机制与Seq2seq模型做下笔记。 机器翻译和数据集 机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,...
文章目录1 机器翻译及相关技术1.1 机器翻译基本原理1.2 Encoder-Decoder1.3 Sequence to Sequence模型1.4 Beam Search2 注意力机制与Seq2seq模型2.1 注意力机制2.2 注意力机制的计算函数介绍2.3 引入注意力机制的Seq...
注意力机制与Seq2seq模型;Transformer 1.机器翻译及相关技术 机器翻译和数据集 机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出...
机器翻译 机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。...
机器翻译和数据集 机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器...Sequence to Sequence模型 模型: 训练预测 具体结构: Beam Search 简单greedy search:
深度学习入门-4(机器翻译,注意力机制和Seq2seq模型,Transformer)一、机器翻译1、机器翻译概念2、数据的处理3、机器翻译组成模块(1)Encoder-Decoder框架(编码器-解码器)(2)Sequence to Sequence模型(3)集...
机器翻译 1.定义 将一段文本从一种语言自动翻译为另一种语言, 用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。...
注意力机制与seq2seq模型 Transformer 机器翻译及相关技术 机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个...
一.机器翻译及相关技术 机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列...
机器翻译 指将一段文本从一种语言自动翻译到另一种语言 读取和预处理数据 # 将一个序列中所有的词记录在all_tokens中以便之后构造词典,然后在该序列后面添加PAD直到序列 # 长度变为max_seq_len,然后将序列保存在...
自注意力和位置编码 - 在自注意力中,查询、键和值都来自同一组输入。 - 卷积神经网络和自注意力都拥有并行计算的优势,而且自注意力的最大路径长度最短。但是因为其计算复杂度是关于序列长度的二次方,所以在很长的...
在实践中,当给定相同的查询、键和值的集合时,我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来, 捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)...
想象一下,有了注意力机制之后,我们将词元序列输入注意力池化中, 以便同一组词元同时充当查询、键和值。具体来说,将比较的是卷积神经网络、循环神经网络和自注意力这几个架构的计算复杂性、顺序操作和最大路径...
注意力机制(Attention Mechanism)是一种在计算机科学和机器学习中常用的技术,可以使模型在处理序列数据时更加准确和有效。在传统的神经网络中,每个神经元的输出只依赖于前一层的所有神经元的输出,而在注意力...


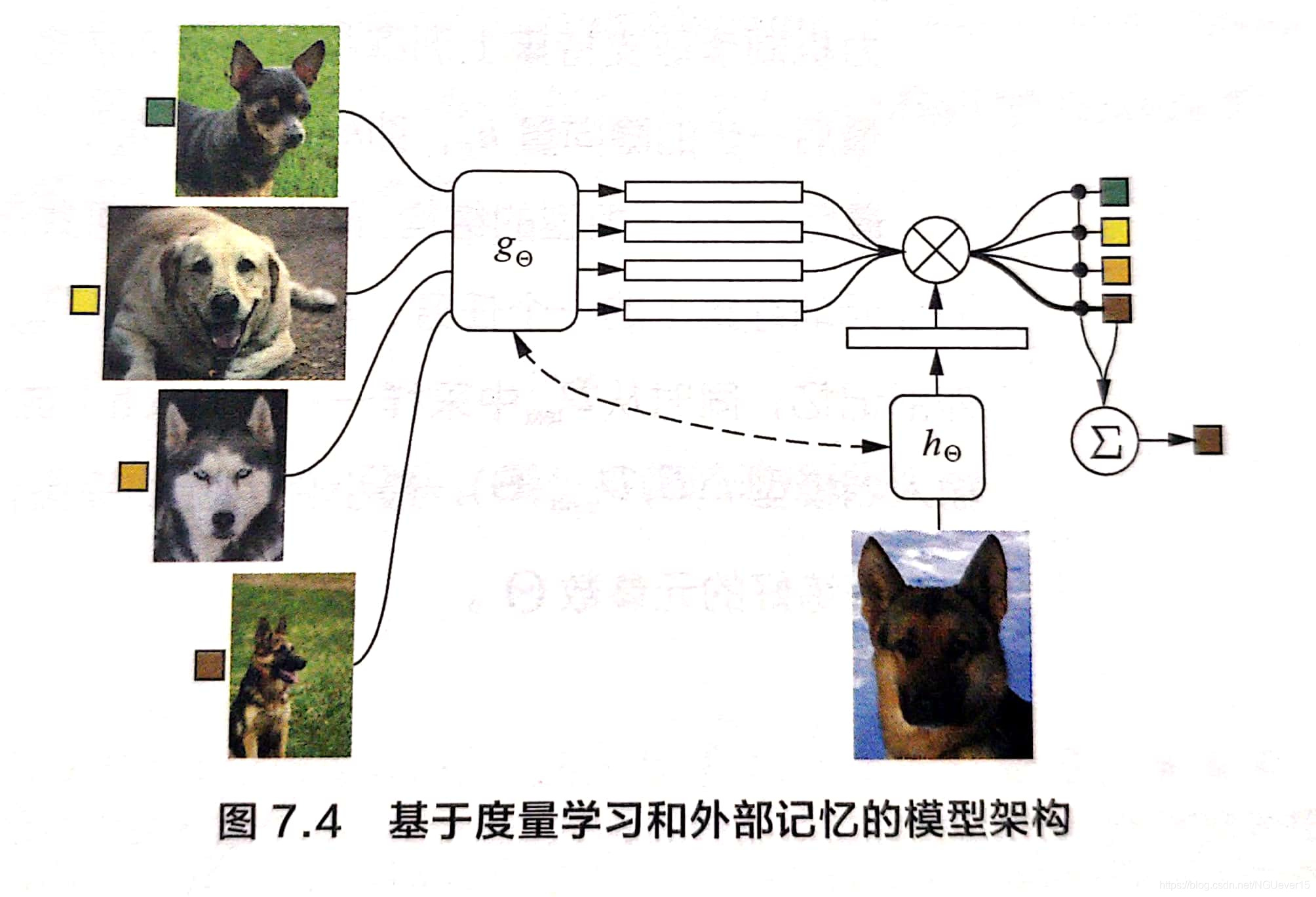
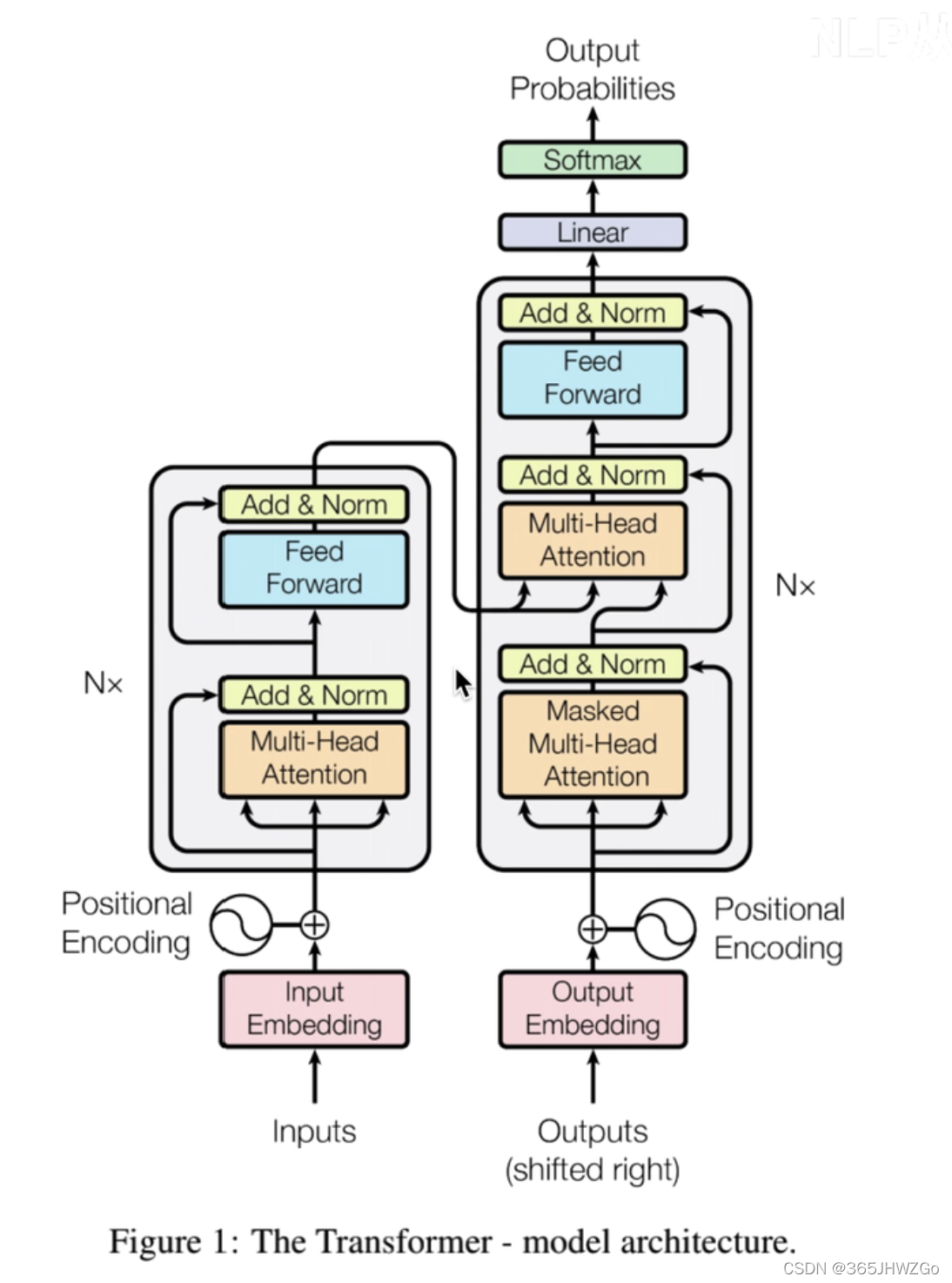
多头注意力机制的第1步是创建查询矩阵、键矩阵和值矩阵。我们已知可以通过将输入矩阵乘以权重矩阵来创建查询矩阵、键矩阵和值矩阵。我们可以看到,每个解码器中的多头注意力层都有两个输入:一个来自带掩码的多头...
原始数据点连成的线段如图中所示,使用Nadaraya-Watson插值拟合的和采用拉格朗日拟合曲线比较接近,在图中为连续光滑的曲线。==以后可能经常性的会求出随机变量的均值与方差进行比较以说明理论背后的逻辑。...

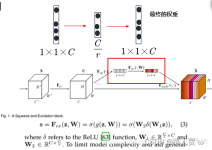
无论是我们的语言处理、还是图像处理等,我们的输入都可以看作是一个向量。通过Model最终输出结果。这里,我们的vector大小是不会改变的。然而,我们有可能会遇到这样的情况:输入的sequence的长度是不定的怎么处理...

推荐文章
- linux查看系统编码和修改系统编码的方法_linux 机器编码设置-程序员宅基地
- 企业微信小程序_小程序开发工具及真机调试_host配置及代理_微信开发者工具 本地代理-程序员宅基地
- 详解C语言自定义类型——结构体struct_struct结构体定义和声明-程序员宅基地
- kettle-基本使用_kettle箭头-程序员宅基地
- python输入两个数值区间若能合并区间_【python-leetcode57-区间合并】插入区间-程序员宅基地
- IDM免费安装注册使用,两步注册成功_idm注册-程序员宅基地
- SM4国密算法原理及python代码实现_根据sm4_s计算sm4_sbox_t-程序员宅基地
- DMA映射 dma_addr_t-程序员宅基地
- XSS跨站脚本攻击漏洞_小明是公司的开发工程师,发现公司网站存在xss漏洞,通过修改javascript代码进-程序员宅基地
- 软件体系结构_采用结构化技术开发的软件是否具有体系结构?-程序员宅基地